Over 30 hours of video lessons, filled with concepts and live examples covering all major areas of data processing and engineering.

Tons of exercises and projects that replicate the real-life data engineering process. You will learn how to assess big data technology based on data requirements.
Ask questions day or night. Post your projects to get feedback. Share resources and learn from your fellow students.
All the course videos and assignments are available for offline use. You also have lifetime access to the curriculum, which is regularly updated.
The data engineer gathers and collects the data, stores it, does batch processing or real-time processing on it, and serves it via the database to a data scientist who can easily query it.
The data scientist interprets and extracts meaning from data using exploratory data analysis and machine learning, and communicates these findings to other teams.
The machine learning engineer takes trained models and prepares them for the production environment by creating APIs, scheduling jobs as well as logging and monitoring.
30 hours of video lessons, 200 hours of assignments and 100 hours for the capstone project.
You should have a strong command of Python, SQL, and the Command Line. You can learn these subjects for free via Codecademy.
We have converted a handful of early lectures to articles and posted them via Medium. Here is a sample coding lab from our first unit as well.
If you need a custom invoice, syllabus, letter of acceptance or certificate of completion, simply email me.
Yes, as soon as you sign up, you will get immediate access to the entire video series and an invitation to the student community.
Yes, all students have lifetime access to the course. You can start the course the minute you buy it, or a year later – it's up to you.
As there are not really any structured data engineering bootcamps, the most comparable programs would be graduate certificates teaching big data technologies. We like the one offered by the University of Washington. Ours will be more affordable, flexible and include newer technologies. We do understand that some people and employers prefer going with name-brand institutions.
This course was built by a lean team of industry professionals. We all enjoy teaching and learning new things, so we thought we could make something amazing to help fill a major gap in the technology space.

Felix Raimundo
Curriculum Contributor
Data Engineer @ Tweag

Ashish Nagdev
Curriculum Contributor
Senior Data Engineer @ Citi
If you need to learn data engineering fast, there’s no better way to do it than with personal advice and one-on-one technical feedback.
The Mentorship Plan is for students who need to up their skills as quickly and efficiently as possible. While all students will have access to feedback and reviews in the Student Community, the Mentorship students will also get six one-on-one sessions over Skype, where we’ll screen share code you’re working on and zoom in on the topics that will personally help you the most.
These are example questions you might ask:
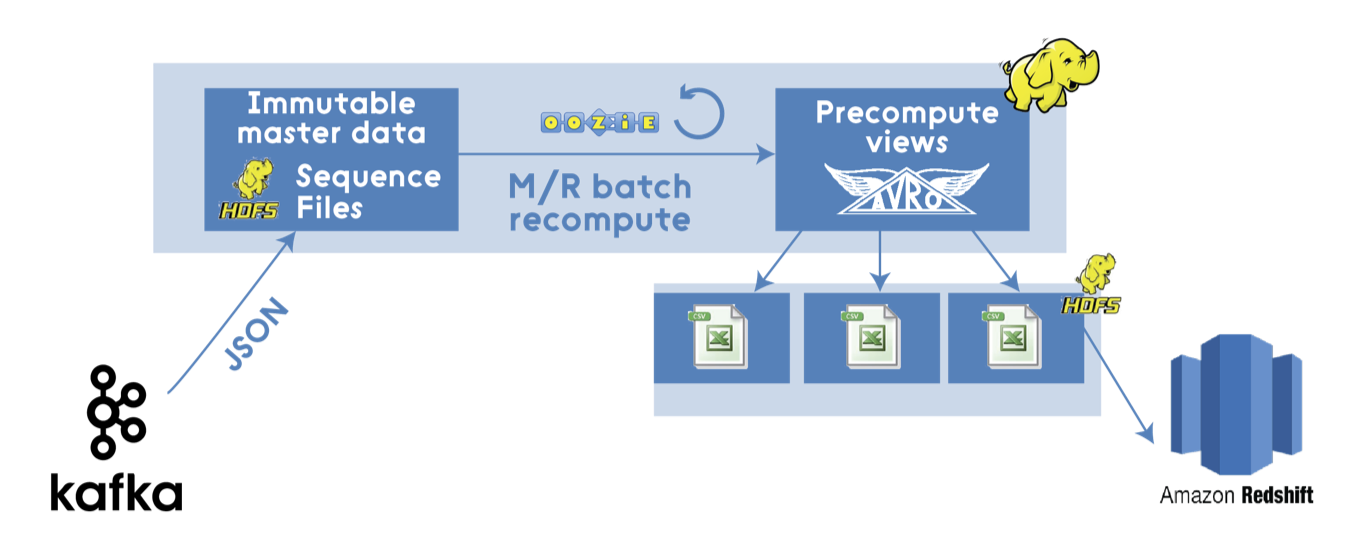 A modern Hadoop-based MapReduce pipeline.
A modern Hadoop-based MapReduce pipeline.
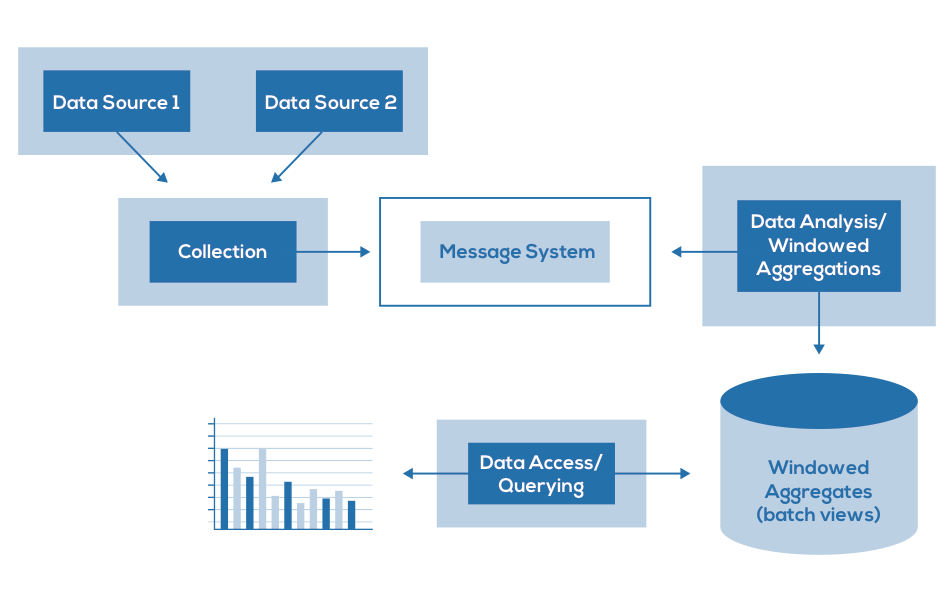
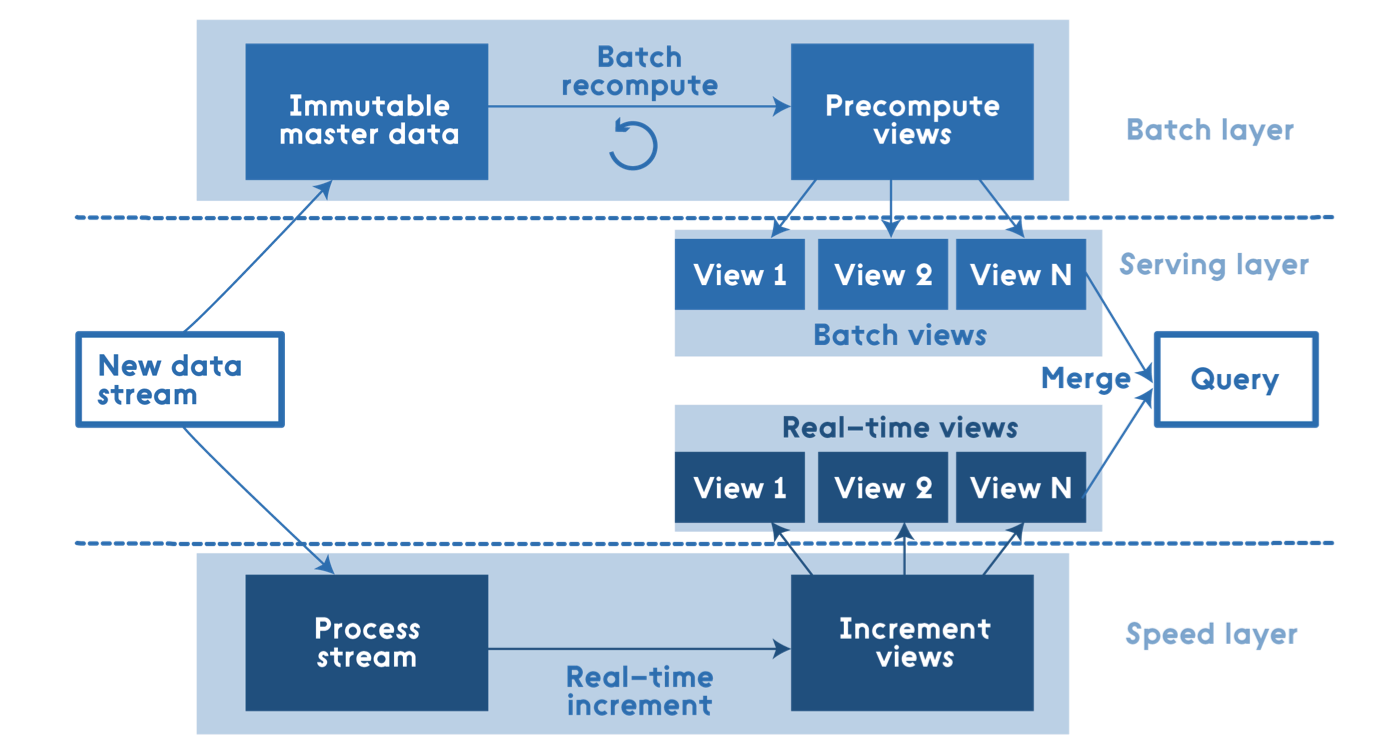 High-level perspective of Lambda Architecture.
High-level perspective of Lambda Architecture.
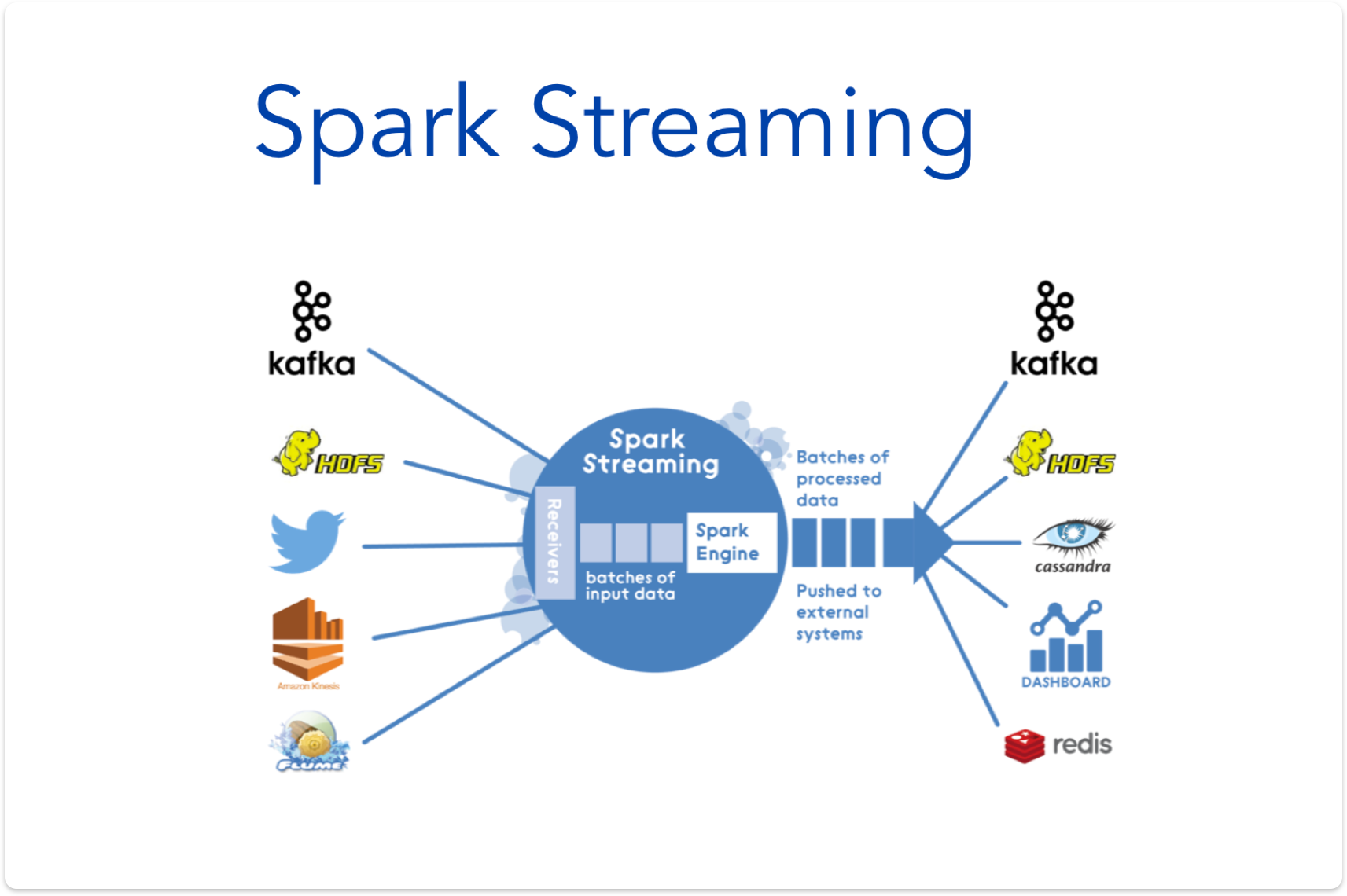
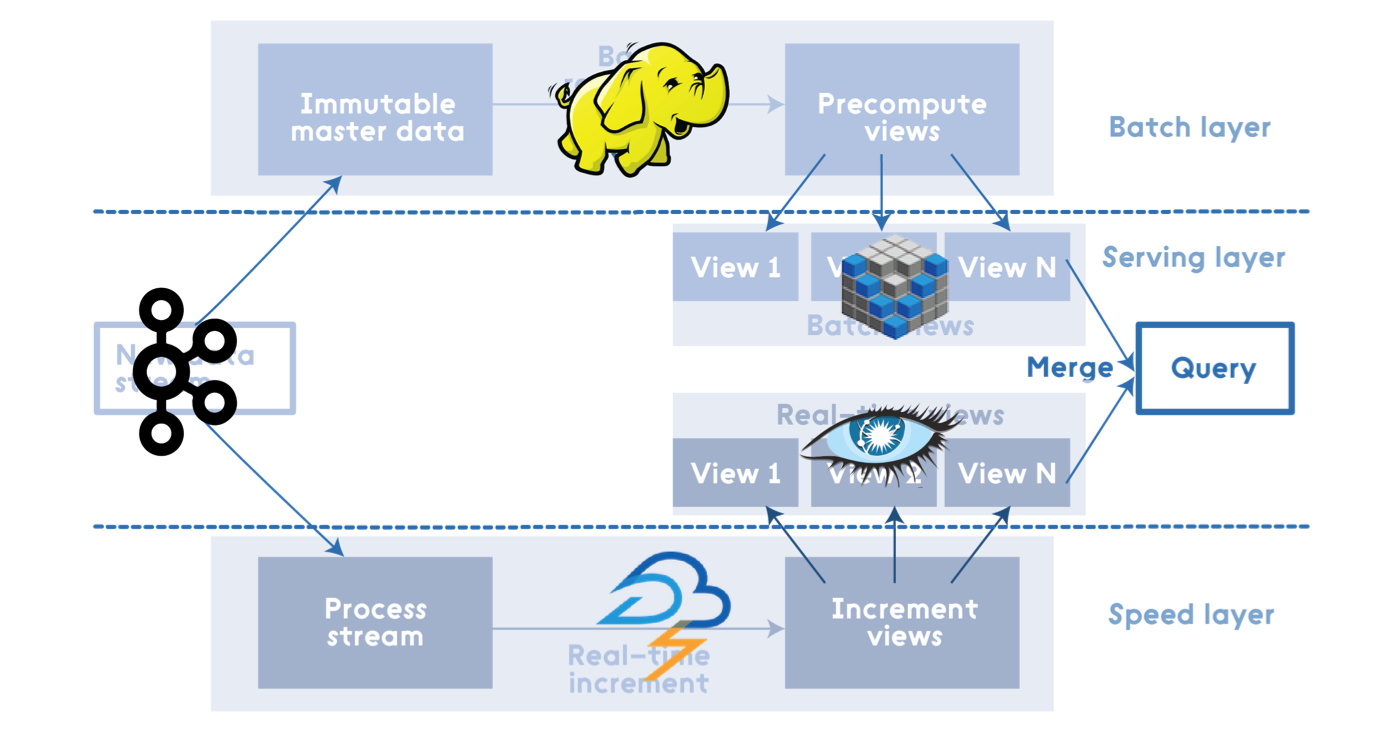 Enhanced Hadoop pipeline with Storm, Cassandra and Voldemort.
Enhanced Hadoop pipeline with Storm, Cassandra and Voldemort.