
Over 30 hours of video lessons, filled with concepts and live Python examples covering all major areas of data science and machine learning.
Tons of exercises and projects that replicate the real-life data science process. You will be fully equipped for the demands of the job market.
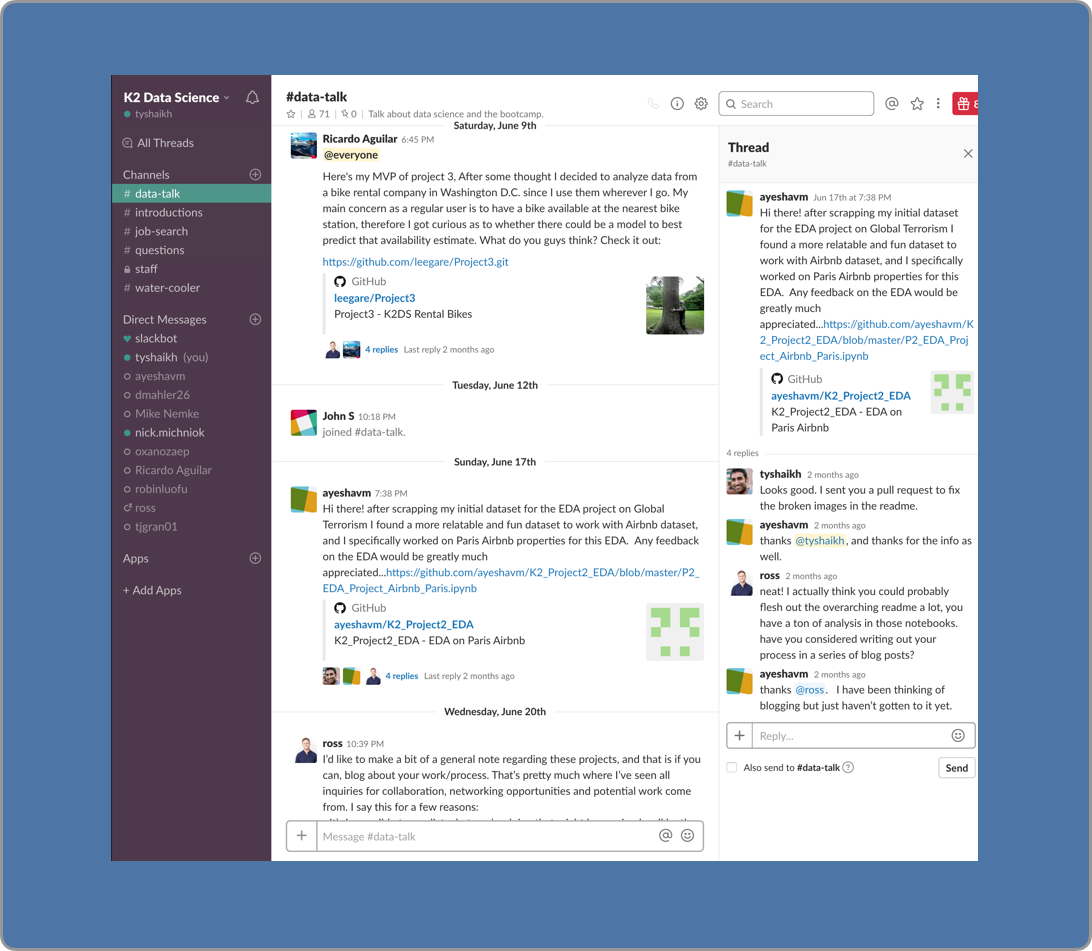
Ask questions day or night. Post your projects to get feedback from teaching assistants. Share resources and learn from your fellow students.

1-on-1 mentorship with a professional data scientist. You will learn best practices, take your projects to the next level and be ready for technical interviews.
All the lecture videos, guided Jupyter notebooks, and assignments are available for offline use. You also have lifetime access to the curriculum, which is regularly updated.

Learn fast with an experienced data scientist there to guide you each step of the way.
These are example questions you might ask:

Daniel Cardella
Portfolio Manager
KLR Group
"I was in the first cohort and have witnessed the development of the Curriculum since I first began and believe it to be continuing to improve from a very good to an excellent base. The highlight of the program, undoubtedly, was the mentorship experience. Meeting with my mentor twice a week for numerous months while I coded my projects has proven to be invaluable in shortening the learning cycles. The program surpassed my already high expectations."

William Ryan
Research Associate
U.C. Berkeley
"They have produced an excellent curriculum which teaches data science effectively — lectures and exercises get you familiar with the material, and then project-based work helps you apply it. The mentors and TAs were responsive and helpful, and proactive in offering help and advice. By the end of the program, you’ll be familiar with pretty much every tool and technique used by data scientists in their day-to-day work."

Fidel Cuevas
Quantitative Developer
UBS
"You'll work with Python and learn to use machine learning to predict a variety of outcomes in computer vision, forecasting, clustering, and classification. For some perspective: I took approximately 4 months to finish the curriculum and found a new role with a substantial increase in compensation after just 22 days of searching. This is a great option for any student or professional with the motivation to do great work."
3+ years of work experience in an analytical or technical role
This could be as a data analyst, software engineer or applied scientist, among many other careers.
A quantitative academic degree
Most companies prefer candidates with strong academic coursework and research experience. A MS degree or PhD is usually required for most positions.
Experience with computer programming
You do not need professional experience, however, you should have spent time on your own learning and building programs.
These are not strict criteria. We always evaluate each applicant individually and look out for motivated, non-traditional candidates. Check our student page to see the variety of backgrounds.
At a minimum, 700 hours of learning, completing exercises and building projects.
It can take anywhere from 4-12 months to finish, depending on your prior knowledge and weekly commitment.
You can pay the tuition upfront or pay over 6 months.
The payment plan costs 20% more than the upfront tuition.
Everyone must complete the coursework and exercises in the Foundations program.
In addition, employers are looking for applicants with the following characteristics:
Once you start the course, you are paired off with a data scientist who will serve as your mentor.
You meet with your mentor every week or every other week via a video call.
Most students discuss new concepts they learned and the challenges they are facing with open-ended projects.
We all enjoy teaching and mentoring the next generation of data scientists.
We split our time between data science/engineering careers and working at K2.

Benjamin Bertincourt
Data Scientist @ Teachable

Nelson A. Colon
Applied Scientist @ Microsoft

Samuel Turner
Data Scientist @ Upwork

Michael Crown
ML Engineer @ Nike

Ross Blanchard
Software Engineer @ Helix

Ty Shaikh
Program Manager



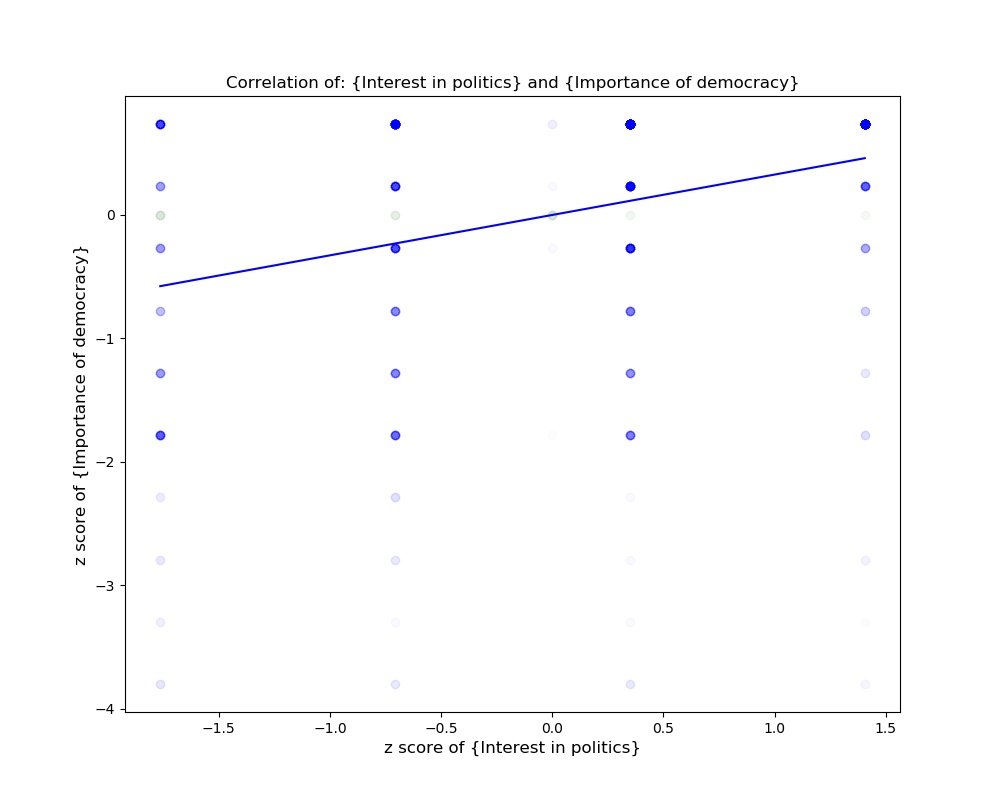 Student examines politics, democracy and wealth.
Student examines politics, democracy and wealth.
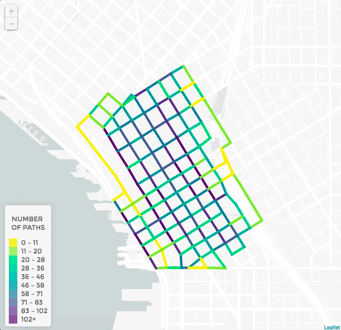
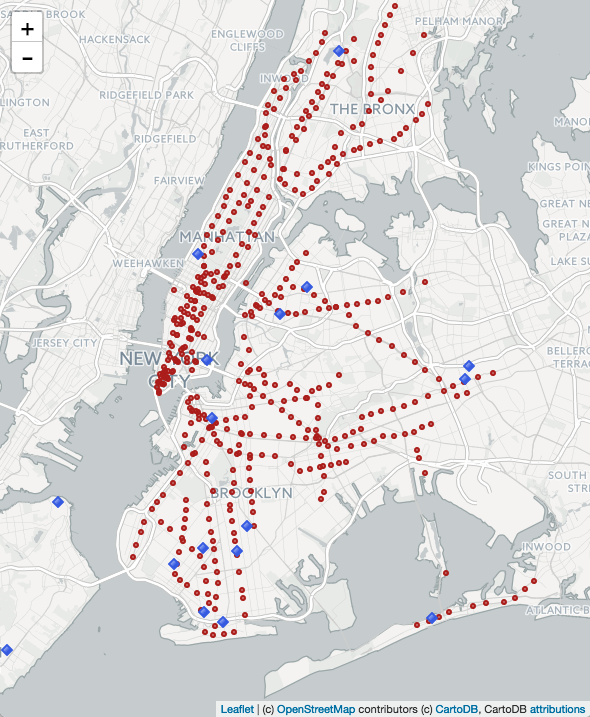 Student builds a NYC school recommendation engine.
Student builds a NYC school recommendation engine.
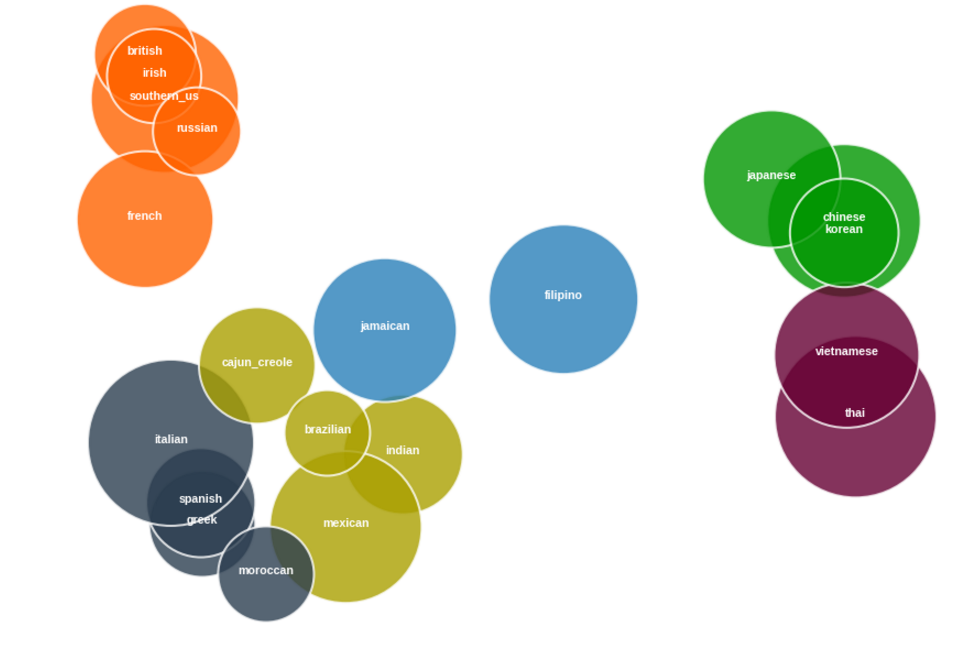 Student uses clustering and similarity metrics between cuisines.
Student uses clustering and similarity metrics between cuisines.